

A new study highlights the role of timing in associative learning

This post presents some newer information regarding the basic science of learning. In a previous post Pavlovian conditioning, reward prediction errors, and the role of the dopamine system was reviewed in some detail. The post can be found here:
An additional review concerning dopamine and the role of the reward system in addiction can be found here:

A recent study published in the journal Nature Neuroscience (Burke et. Al Feb. 2026) reported findings from a relatively straightforward series of experiments using well known principles of cue – response conditioning as a paradigm for associative learning.
The studies explored changes in the timing of reward intervals. One group with a short time between repetition of the cue – reward pair and the other with a longer wait time. The cue used was an audible tone followed in 0.25 seconds by the reward, a drop of sugar solution.
The behavior recorded was licking of the sugar dispenser which could be electronically recorded. Corresponding dopamine release was also measured by an implanted device.
Implications of the findings for existing models of associative learning, computational biology, and addiction studies are briefly explored.
Learning is defined as the time or number of repetitions required until the animal responded to the cue (buzzer) rather than the reward itself (sugar). In all studies sessions were conducted for one hour each day for a total of eight days.
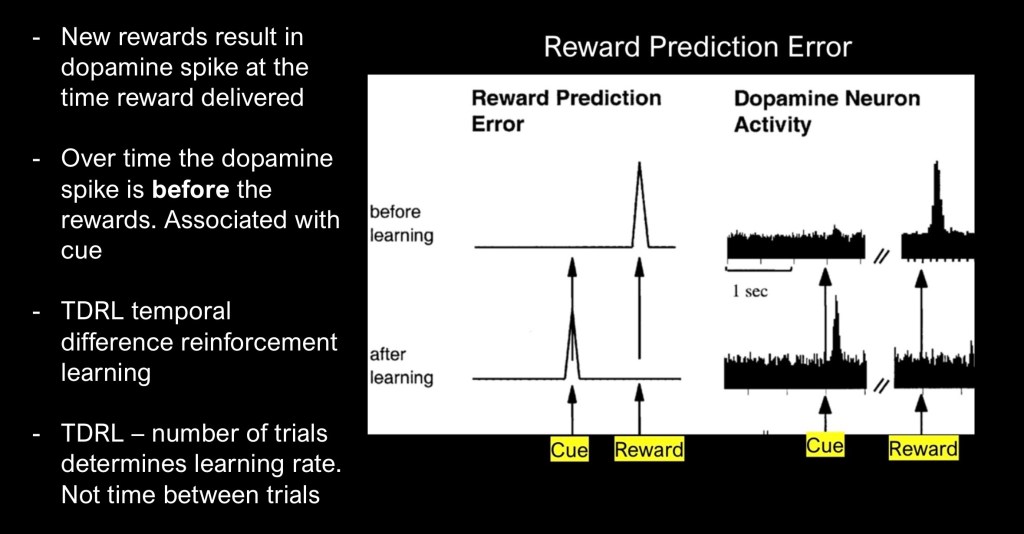
Reward prediction error (RPE) is a well known property of behavioral psychology and neurobiology. It occurs whenever an expected reward, or aversive stimulus is new or does not match predicted outcome. It is a core component of learning and adaptation.
Dopamine is not, as some assume, the “pleasure transmitter”. Dopamine encodes a motivational signal to seek out rewarding stimuli or to avoid aversive ones. Anyone who has trained a dog to “sit” or stay knows how this works. At first the dog has no idea what the treat is for. When paired with the command, over time Fido will learn to sit even when no treat is presented. The dopamine signal has been transferred to the command and not the reward.
TLDR is the dominant theoretical construct explaining these relationships. It can be expressed as a mathematical equation. This has been explored in detail in the earlier post and references. An important point is that the TLDR model considers the number of trials required to produce measured outcomes, not the time and spacing between trials.
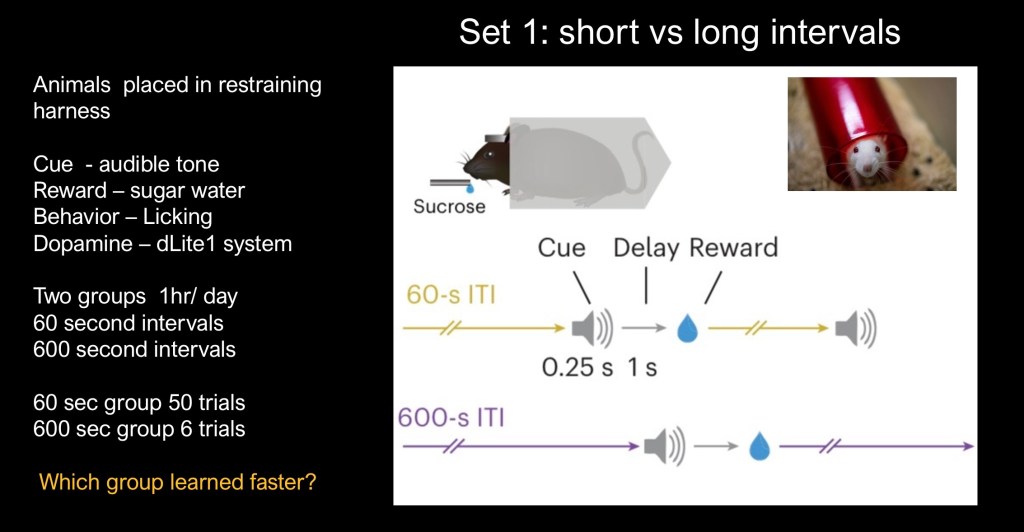
The first set of conditions divided the animals into two groups. Both groups received the sugar water 1 second after the audible tone. In the first group the cue-reward trial was repeated every 60 seconds. In the second group the cue-reward trial was repeated every 600 seconds. So the second group had a 10x longer space between rewards. Licking was recorded along with dopamine levels.
The session was carried out for one hour after which the animals were returned to their containers. The sessions were carried out for eight consecutive days.
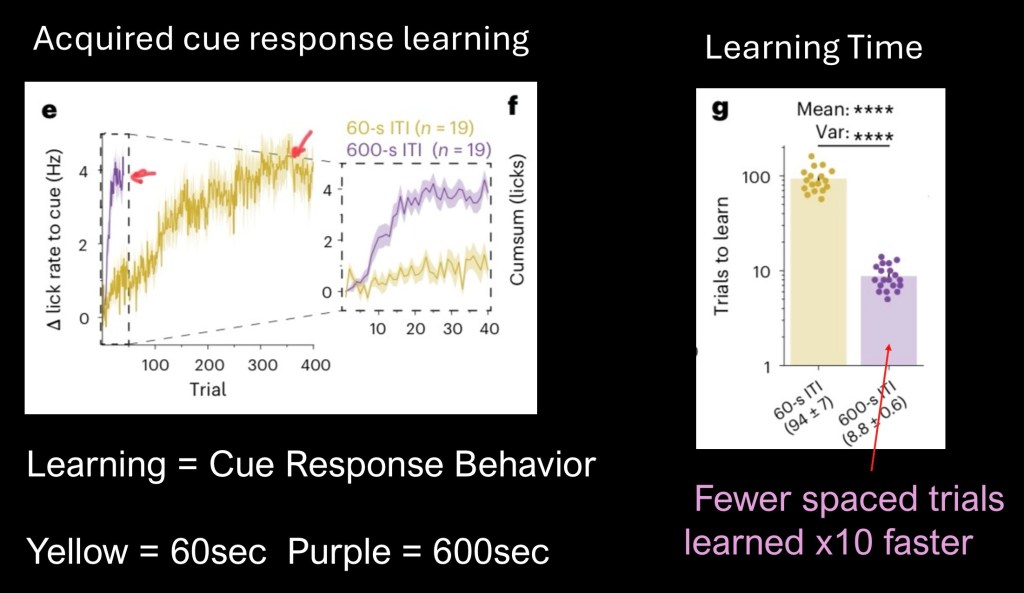
Averaged behavioral results are above.
Yellow – 60sec group total of 400 trials
Purple – 600 sec group. Total of 40 trials
Learning time is defined as the time from start to stable plateau when the behavior transfers from reward to cue (animal starts licking at the tone, before the sugar water)
The first graph and closeup reflect number of trials to end point. The 600 second group reached plateau at only 40 trials. The 60 second group took 400 trials, requiring 10x more repetitions to learn the association.
Τhe bar graph represents time required for each group to reach the end point. The 600sec group learned at a 10x higher rate then the group with more frequent trial repetitions.
These results are striking and seem counterintuitive. It has long been held that more repetitions or quantity consumed is the determining factor driving learned behavior.
The next data set looks at dopamine as it relates to observed behavior. This study employed a novel system capable of in vivo recording of near instantaneous local dopamine levels.
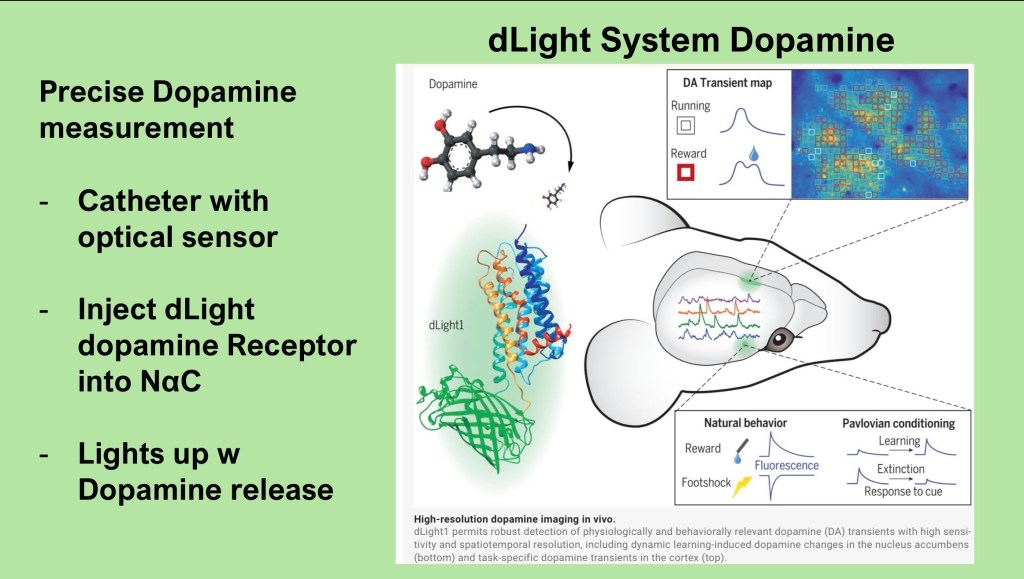
The dLight system utilizes a synthetic biologically inert dopamine receptor to which a fluorescent marker has been attached. A catheter is advanced into the region of interest in the mouse brain. Following a post operative rest period the agent can be infused. A light microsensor can then record activation by extracellular dopamine release.
The system is capable of high resolution mapping and time/activity curves.
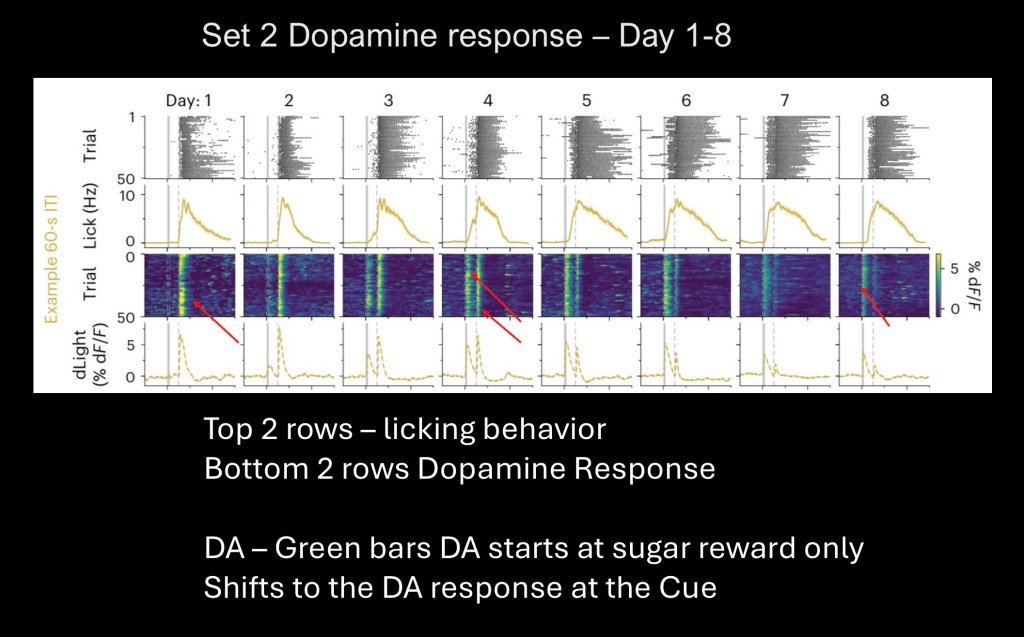
Data from the 60 group shown above. Vertical blocks represent averages by day. The upper two rows are summary raw data of licking behavior and summary graph.
The lower two rows represent dopamine levels in the nucleus accumbans. Beginning to the far left a single vertical green line is dopamine release in response to the sugar reward.
Beginning from the second row an adjacent band is seen. This is dopamine in response to the cue followed by the food reward. Continuing to the right cue response increases while dopamine in response to the reward decreases. The pattern is as predicted for reward prediction error.
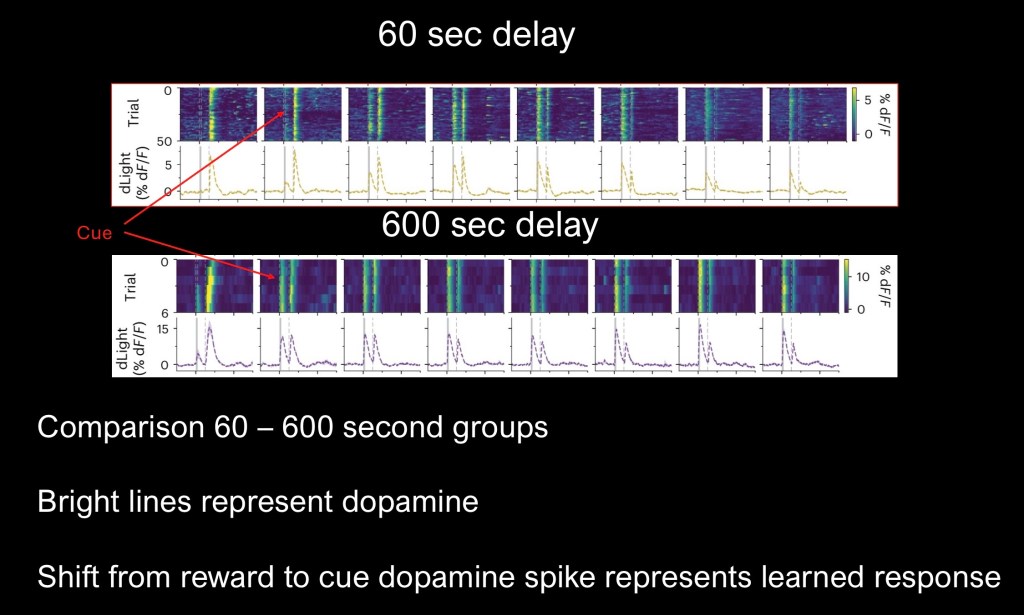
Comparison of the 60sec group (top) and the 600 second group (lower).
Shift of the dopamine response from reward to cue is seen earlier for the 600sec delay group. Activity is present on day one despite 1/10 the number of daily trials.
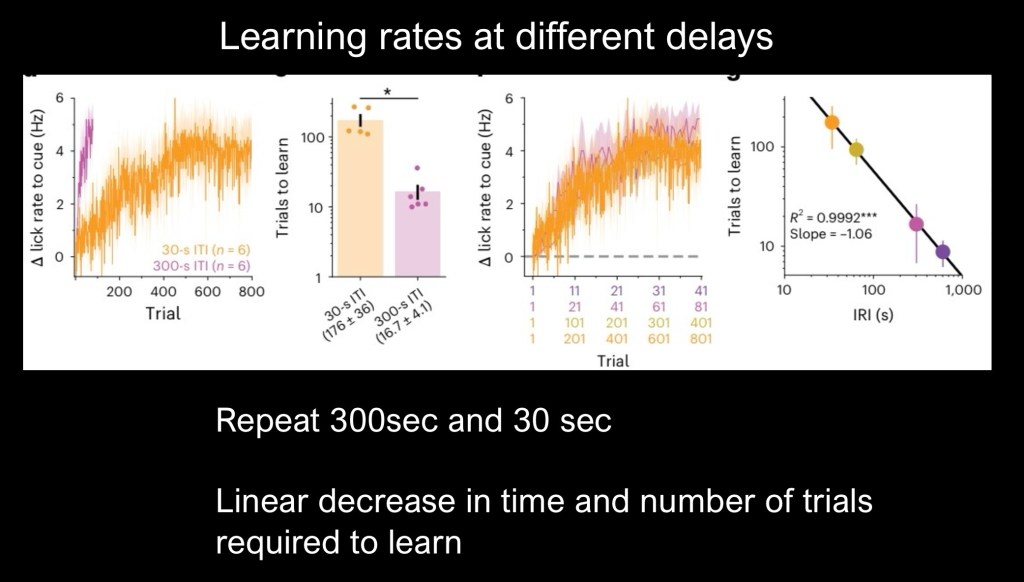
To further confirm and explore the relationship the study was repeated with 30 second and 300 second inter reward intervals (IRI).
On the left is percent change in lick rate and number of trials on the horizontal axis. Purple represents the 300 second group. Again longer delays resulted in faster learning at 1/10 the number of trials.
Plot on the far left shows a linear relationship for both conditions.
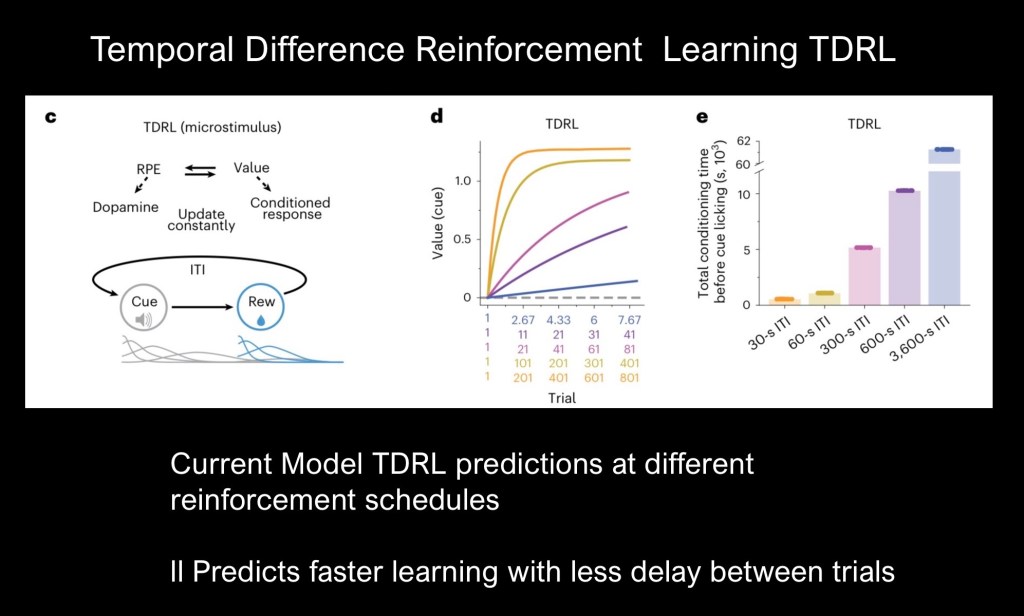
The authors explored theoretical models of reward prediction errors (RPE) and associative learning. The prevailing TDRL model can be expressed as a mathematical equation further discussed below and described in an earlier post linked to above.
TDRL assigns a value to a given reward. Value is a state function at a given time and not fixed. RPE and Value are related as a prediction error results in updated Value.
Using the TDRL equation predictive curves can be generated using different interval cue spacing (d). Bar graphs predicting conditioning time for various spacing intervals are shown (e ). TDRL predicts increasing conditioning time required as RTR interval increases. This is the opposite of what has been shown in the current study.
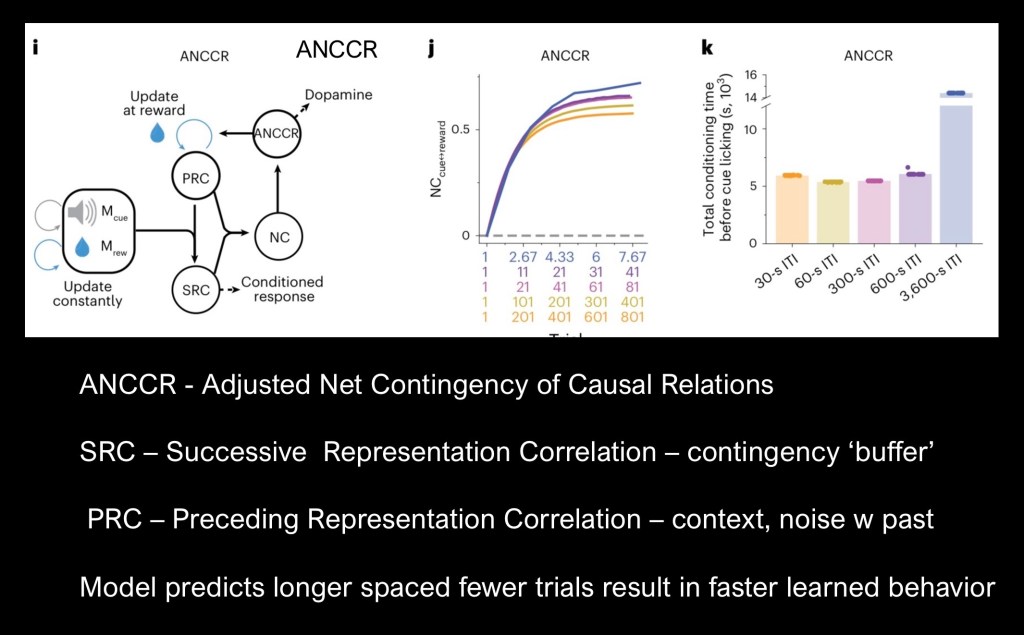
The authors have proposed a model accounting temporal spacing in associative learning. The Adjusted Net Contingency of Causal Relationships (ANCCR) model correctly predicts outcomes with fewer trials needed to attain behavioral and dopamine cue transfer (d). There is a threshold as 3600 second delay was shown to be less effective (e ).
In the above diagram SRC, PRC, and NC refer to complex Contingencies in which retrospective adjustments are made about the cue and reward based on prior experience.
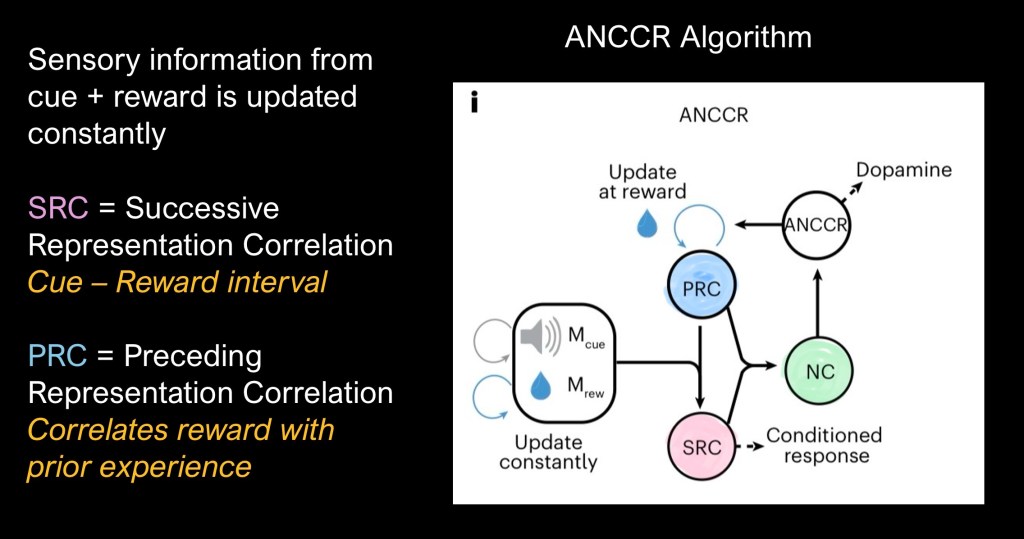
This conceptual diagram describes the ANCCR model. When a cue and reward event occur the cue-reward interval is processed as the SRC. The Net Correlation (NC) acts as a buffer based on averages of past experience and an updated PRC results.
In contrast with earlier models ANCCR is retrospective rather than prospective. It looks back after receiving the reward to find similar causes or cues. Longer intervals between trials allows for a sharper distinction between relevant events. Closely spaced trials are more “cluttered”.
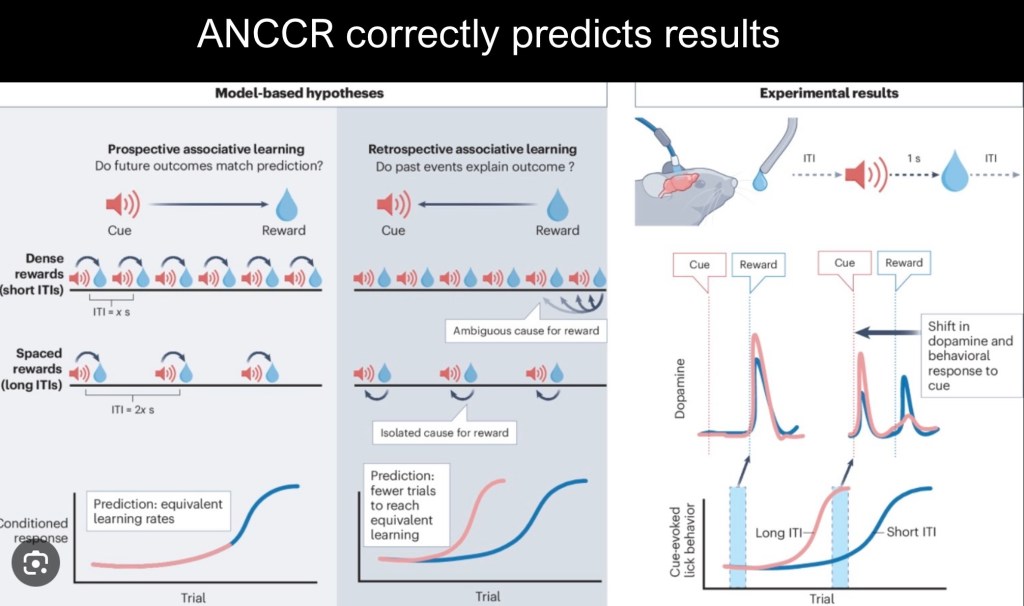
Illustration of the differences in assumptions between ANCCR and earlier models. Prospective models ask “will outcomes in the future meet current predictions?” Retrospective models ask “do past experiences match current outcomes?” It is a subtle difference yet it matters a great deal in basic understanding in many fields including addiction studies.

TDRL relies on Value calculations where the current and past value of rewards determines subsequent predictions. In more formal terms a delay discounting term ν is introduced with time sensitive factors. As you go back in time past events become exponentially smaller.

ANCCR relies on contingencies in which cumulative past experiences buffer new information. Timing affects informative value. In associative learning this is proportional to the reward-reward interval divided by the cue-reward interval. So when the time between the buzzer and the sugar reward is short, 1 second in this series and the time between trials is lengthened informational value increases.
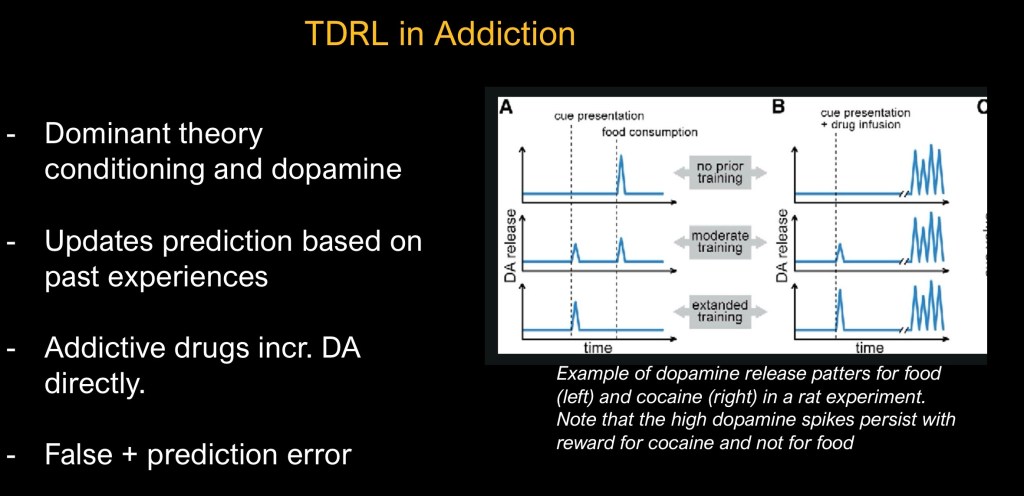
Addictive drugs have distinctive intrinsic properties differentiating them from other natural rewards. They act by either directly raising dopamine levels (cocaine, amphetamines) or indirectly (alcohol, opiates). This results in an overstimulated mesolimbic reward pathway along with downstream effects resulting in deficits in executive function, emotional regulation, and stress systems.
Combined effects result in progressive loss of control over use. Cue related drug craving is a primary mechanism driving continued use and relapse.

In associative learning dopamine surges and conditioned response transfer from the reward to cue. It has been the dominant model that the number of trial repetitions is the primary determining factor driving conditioned behavior.
TDRL model has a high predictive value however it has more recently been questioned in ability to account for changes in the timing between trials. This study compared shorter spacing (60 sec, 30sec) with longer spacing (600 sec, 300 sec). Behavior (licking sugar water dispenser) and NaC dopamine (dLite) were measured outcomes.
Results found a proportional decrease in the number of trials needed to learn and transfer behavior along with dopamine spike from the reward to cue. This is counter intuitive and not accounted for in standard models. Common wisdom holds that more practice results in greater learning .

The authors propose an alternate model accounting for increased learning power with longer delays. ANCCR involves a more complex mechanism in which contingencies formed as a composite of past experiences acts as a buffer incorporating new information.
Reinforcement in ANCCR is not simply a prediction error. It is a calculation in the context of composite experience. This explains the failure of extinction based therapy in SUD as reinstatement is based on deeply rooted part experience.

This has significant implications for addiction studies. While substance use disorders are far more complex that the simple laboratory experiments here much of the basic science of addiction relies heavily on animal models and conditioning. There has been little attention paid to the effects of time between rewards or therapeutic interventions on outcomes. This suggests significant gaps in understanding of addiction and relapse. Future studies taking temporal factors into account may reveal previously missed associations.
Binge pattern use has historically received insufficient attention. The highly reinforcing nature of high volume intermittent use is better understood by ANCCR. Research outcomes such as average daily volume, number of use days per week and severe withdrawal symptoms most often miss problematic binge use.
ANCCR posits a model in which low frequency rewards have heavier weight when baseline conditions are less rewarding. This suggests therapeutic interventions targeted at creating a rewarding environment to counterbalance powerful cue driven impulses. It also implies that a long term lower frequency strategy may be more effective than short term “bursts” of therapy. Links between internal or external cues and substance use are causal factors not merely slips or lapses in judgement.

J Kay 4/26
Thank you for your time in reviewing this post. For information and educational purpose only. Images and data obtained from sources freely available on the World Wide Web. This post should not be considered medical or professional advice.
jeffk072261@gmail.com
References
Burke, D.A., Taylor, A., Jeong, H. et al. Duration between rewards controls the rate of behavioral and dopaminergic learning. Nat Neurosci (2026). https://doi.org/10.1038/s41593-026-02206-2
https://www.nature.com/articles/s41593-026-02206-2#citeas
………………………………………………..
,
Ultrafast neuronal imaging of dopamine dynamics with designed genetically encoded sensors
TOMMASO PATRIARCHI HTTPS://ORCID.ORG/0000-0001-9351-3734, JOUNHONG RYAN CHO HTTPS://ORCID.ORG/0000-0001-9542-716X, KATHARINA MERTEN HTTPS://ORCID.ORG/0000-0002-0197-0186, MARK W. HOWE, […] , AND LIN TIAN HTTPS://ORCID.ORG/0000-0001-7012-6926+12 authors Authors Info & Affiliations
SCIENCE
31 May 2018
Vol 360, Issue 6396
https://www.science.org/doi/10.1126/science.aat4422
TDRL
https://helioxpodcast.substack.com/p/your-brain-is-lying-to-you-and-thats
Anna B. Konova, Ahmet O. Ceceli, Guillermo Horga, Scott J. Moeller, Nelly Alia-Klein, Rita Z. Goldstei
Reduced neural encoding of utility prediction errors in cocaine addiction
Konova et al., 2023, Neuron 111, 4058–4070
December 20, 2023 ª 2023 Elsevier Inc.
https://doi.org/10.1016/j.neuron.2023.09.015
https://www.cell.com/neuron/pdfExtended/S0896-6273(23)00700-6
https://psychiatryonline.org/doi/full/10.1176/appi.ajp.2013.12091257
Reduced Neural Tracking of Prediction Error in Substance-Dependent Individuals
Jody Tanabe, Jeremy Reynolds, Theodore Krmpotich, Eric Claus, Laetitia L. Thompson, Yiping P. Du and Marie T. Banich
American Journal of Psychiatry
https://doi.org/10.1176/appi.ajp.2013.12091257
……………………………………………………
Prefrontal Cortex Fails to Learn from Reward Prediction
Errors in Alcohol Dependence
Soyoung Q Park,1,2* Thorsten Kahnt,
The Journal of Neuroscience, June 2, 2010• 30(22):7749 –7753 • 7749
……………………………………………………………
Less is more: prolonged intermittent access cocaine self-administration produces incentive-sensitization and addiction-
like behavior, Alex B. Kawa, Brandon S. Bentzley
Psychopharmacology (Berl) . 2016 October ; 233(19-20): 3587–3602. doi:10.1007/s00213-016-4393-8.J

Leave a comment